Database transactions are a crucial aspect in application development, especially in projects that demand high data consistency. This article will discuss how to perform database transactions in the service layer (logic), while maintaining clean architecture principles and separation of concerns.
Architecture Towards Database Transactions
In popular architectures like Clean Architecture, Hexagonal Architecture, or Domain-Driven Design (DDD) approaches, separation of responsibilities is key. We generally divide code into several layers, for example Handler -> Service -> Repository. The service layer ideally contains pure business logic without depending on external libraries, while the repository is responsible for database interactions.
However, when implementing database operations that comply with ACID (Atomicity, Consistency, Isolation, Durability) principles, a question arises: where should database transaction logic be placed? In the logic layer or in the repository layer? This often becomes a dilemma for programmers, especially due to challenges arising from architectural principles that push for breaking datastore access through various small and modularized repositories.
note: Atomicity means ensuring that a series of operations in one transaction must either completely succeed or completely fail.
As an illustration, let’s consider the case of money transfer between accounts: “Transfer money from account A to account B, update all related data, and if it fails, cancel the entire process.” There are two common approaches:
Approach A: Transaction Logic in Repository
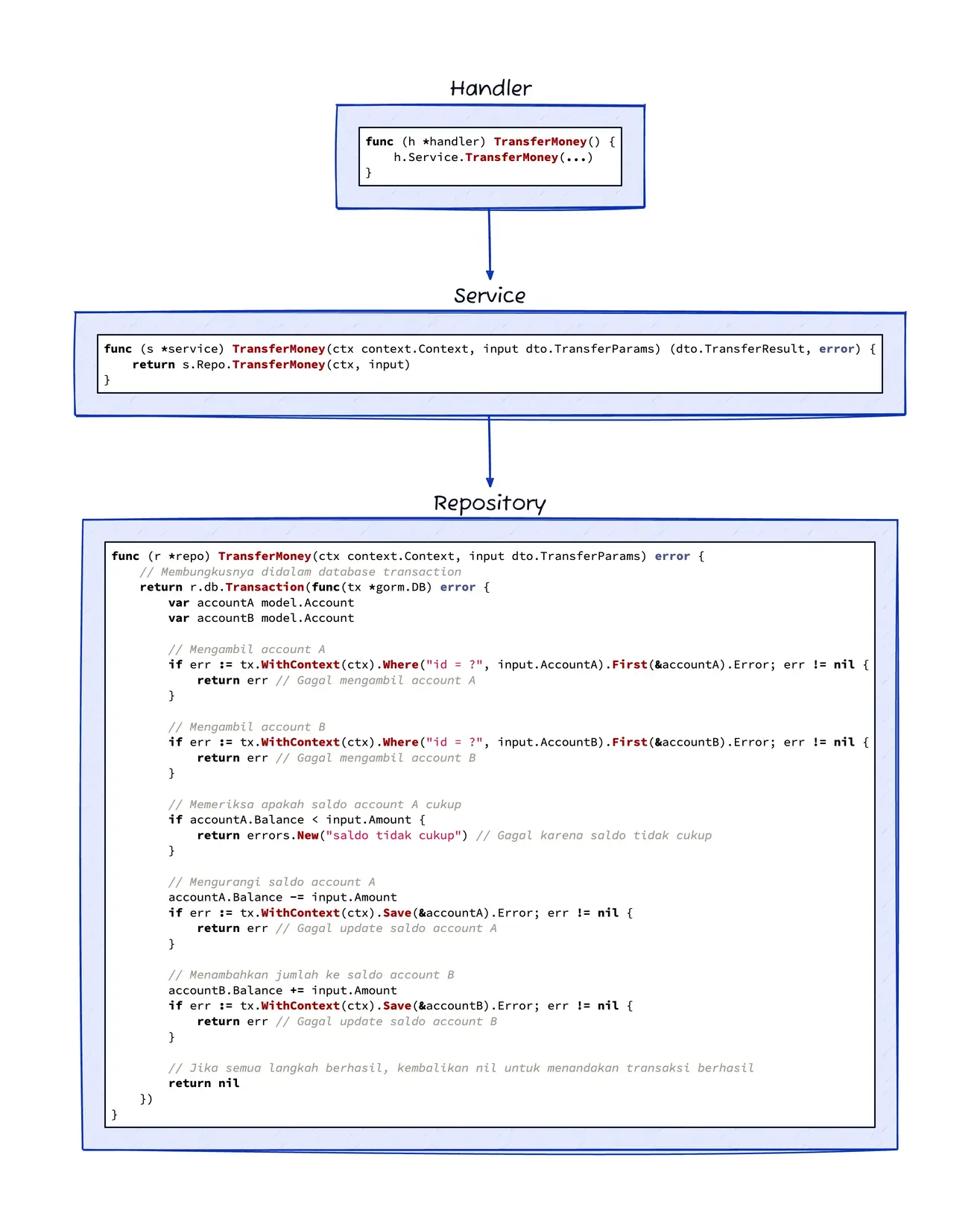
This approach is simple because transactions are started and managed directly in the repository layer. However, this approach has weaknesses: business logic (money transfer) is mixed with data access logic. Imagine if there are additional needs, such as sending balance events to third parties as part of transaction atomicity. Should the repository have dependencies on external services too? This clearly violates separation of concerns principles. Additionally, the service layer becomes very thin, thus eliminating the benefits of unit testing at that layer.
Approach B: Transaction Logic in Service

This approach places transaction logic in the service layer, in accordance with separation of concerns principles. However, its implementation is more challenging. How can the service layer remain independent from database libraries, like GORM, while still being able to manage transactions?
So, where should transaction logic be placed? In the logic layer or in the repository layer?
The answer is in the logic layer. This applies both when mutation processes involve interaction with multiple data sources, and when performing data collection (aggregation). The reason is that business logic determines the valid state of a set of data at a certain time. In other words, if an aggregate is not stored in a complete and valid state, then the business operations performed will be considered inconsistent with applicable business rules. This is also in line with what I’ve read in DDD books. Domain Driven Design
Challenges and Solutions
Keeping the service layer pure from third-party dependencies while managing complex database transactions is indeed difficult. However, several techniques can be applied to overcome this problem, such as using transaction abstractions in the service without having to deal directly with transaction implementation from database libraries.
To maintain service layer purity and still manage database transactions effectively, we will use a layered approach with several key components:
1. DBTX interface
Defines an interface that abstracts database operations, both regular operations and operations within transactions. This allows the service layer to interact with the database without depending on specific implementations. This interface will include methods like Exec, Query, QueryRow, Begin, Commit, Rollback, and others that are needed. The good news is, if you use gorm, this doesn’t need to be done because gorm has already done it (combining both methods into 1). Here I create an example using pgx.
package dbtx
import (
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgconn"
"github.com/jackc/pgx/v5/pgxpool"
)
type DBTX interface {
// method used by pgx for regular operations
Prepare(ctx context.Context, name, sql string) (*pgconn.StatementDescription, error)
Exec(ctx context.Context, sql string, arguments ...interface{}) (commandTag pgconn.CommandTag, err error)
Query(ctx context.Context, sql string, args ...interface{}) (pgx.Rows, error)
QueryRow(ctx context.Context, sql string, args ...interface{}) pgx.Row
// method used by pgx for transaction operations
Begin(ctx context.Context) (pgx.Tx, error)
Commit(ctx context.Context) error
Rollback(ctx context.Context) error
// DBTX combines both...
}
2. PGStore
Provides concrete implementation of the DBTX interface for pgx library. This structure will handle selection between regular database connections or transaction connections. PGStore will check whether the context contains an active transaction (pgx.Tx). If there is, database operations will be performed using that transaction. If not, operations will be performed using the connection pool pgxpool.
NewPGStore functions to create PGStore instances. This function accepts pgxpool pool connections and (optionally) pgx.Tx transaction objects. This will facilitate creating PGStore instances in a consistent and controlled manner.
type PGStore struct {
NonTX *pgxpool.Pool
Tx pgx.Tx
}
// NewPGStore return interface can execute TX and pgx.Pool
func NewPGStore(pool *pgxpool.Pool, tx pgx.Tx) DBTX {
var pgstore PGStore
if tx != nil {
pgstore.Tx = tx
return &pgstore
}
pgstore.NonTX = pool
return &pgstore
}
// Begin implements DBTX
func (p *PGStore) Begin(ctx context.Context) (pgx.Tx, error) {
if p.Tx != nil {
return nil, errors.New("cannot begin inside running transaction")
}
return p.NonTX.Begin(ctx)
}
// Commit implements DBTX
func (p *PGStore) Commit(ctx context.Context) error {
if p.Tx != nil {
return p.Tx.Commit(ctx)
}
return errors.New("cannot commit: nil tx value")
}
// Rollback implements DBTX
func (p *PGStore) Rollback(ctx context.Context) error {
if p.Tx != nil {
return p.Tx.Rollback(ctx)
}
return errors.New("cannot roleback: nil tx value")
}
// Exec implements DBTX
func (p *PGStore) Exec(ctx context.Context, sql string, arguments ...interface{}) (commandTag pgconn.CommandTag, err error) {
if p.Tx != nil {
return p.Tx.Exec(ctx, sql, arguments...)
}
return p.NonTX.Exec(ctx, sql, arguments...)
}
// Prepare implements DBTX
func (p *PGStore) Prepare(ctx context.Context, name string, sql string) (*pgconn.StatementDescription, error) {
if p.Tx != nil {
return p.Tx.Prepare(ctx, name, sql)
}
return nil, errors.New("cannot prefare: pool does not have prefare method")
}
// Query implements DBTX
func (p *PGStore) Query(ctx context.Context, sql string, args ...interface{}) (pgx.Rows, error) {
if p.Tx != nil {
return p.Tx.Query(ctx, sql, args...)
}
return p.NonTX.Query(ctx, sql, args...)
}
// QueryRow implements DBTX
func (p *PGStore) QueryRow(ctx context.Context, sql string, args ...interface{}) pgx.Row {
if p.Tx != nil {
return p.Tx.QueryRow(ctx, sql, args...)
}
return p.NonTX.QueryRow(ctx, sql, args...)
}
3. ExtractTx and injectTx Functions
Next we create helpers that automate the use of NewPGStore.
ExtractTx is used to extract database transaction connections stored in context
injectTx is used for the opposite, which is injecting database transactions into context.
package dbtx
import (
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgxpool"
)
type KeyTransaction string
const TXKey KeyTransaction = "unique-key-transaction"
// ExtractTx extract transaction from context and transform database into dbtx.DBTX
func ExtractTx(ctx context.Context, defaultPool *pgxpool.Pool) DBTX {
tx, ok := ctx.Value(TXKey).(pgx.Tx)
if !ok || tx == nil {
return NewPGStore(defaultPool, nil)
}
return NewPGStore(nil, tx)
}
// injectTx injects transaction to context
func injectTx(ctx context.Context, tx pgx.Tx) context.Context {
return context.WithValue(ctx, TXKey, tx)
}
4. TxManager and WithAtomic Function
WithAtomic automates the use of ExtractTx and injectTx. It’s a wrapper function that will perform ROLLBACK if it fails, and will perform COMMIT database transaction if it succeeds.
In short, when WithAtomic is called, the context will be filled with database transaction, then the context containing database transaction will be used to run subsequent database operations, the repository will automatically use this transaction because it performs ExtractTx every time a database command is executed.
At the logic layer we only deal with WithAtomic.
package dbtx
import (
"log/slog"
"github.com/jackc/pgx/v5/pgxpool"
)
type TxManager interface {
WithAtomic(ctx context.Context, tFunc func(ctx context.Context) error) error
}
type txManager struct {
db *pgxpool.Pool
log *slog.Logger
}
func NewTxManager(sqlDB *pgxpool.Pool, log *slog.Logger) TxManager {
return &txManager{
db: sqlDB,
log: log,
}
}
// =========================================================================
// TRANSACTION
// WithAtomic runs function within transaction
// The transaction commits when function were finished without error
func (r *txManager) WithAtomic(ctx context.Context, tFunc func(ctx context.Context) error) error {
// begin transaction
tx, err := r.db.Begin(ctx)
if err != nil {
return fmt.Errorf("begin transaction: %w", err)
}
// run callback
err = tFunc(injectTx(ctx, tx))
if err != nil {
// if error, rollback
if errRollback := tx.Rollback(ctx); errRollback != nil {
r.log.Error("rollback transaction", slog.String("error", errRollback.Error()))
}
return err
}
// if no error, commit
if errCommit := tx.Commit(ctx); errCommit != nil {
return fmt.Errorf("failed to commit transaction: %w", errCommit)
}
return nil
}
5. WithAtomic and ExtractTx Implementation
Service Layer:
Service layer uses TxManager.WithAtomic to wrap business logic in transactions. This ensures that all database operations in that business logic are performed atomically.
Repository Layer:
Repository layer uses ExtractTx to get the appropriate DBTX object (transaction-based or regular connection) from context. All database operations in the repository are performed through this DBTX object.
So the code will be something like the following.
type service struct {
Repo AccountStorer
TxManager TxManager // helper for transactions becomes additional dependency or can be combined with repo
}
func (s *service) TransferMoney(ctx context.Context, input model.TransferDTO) error {
// shared variable to hold results inside WithAtomic if any
// result := ...
// Wrapping the process with database transaction
txErr := s.TxManager.WithAtomic(ctx, func(ctx context.Context) error {
// Getting account A
accountA, err := s.Repo.GetAccountByID(ctx, input.AccountA)
if err != nil {
return err // Failed to get account A
}
// Getting account B
accountB, err := s.Repo.GetAccountByID(ctx, input.AccountB)
if err != nil {
return err // Failed to get account B
}
// Checking if account A balance is sufficient
if accountA.Balance < input.Amount {
return errors.New("insufficient balance") // Failed due to insufficient balance
}
// Reducing account A balance
accountA.Balance -= input.Amount
if err := s.Repo.UpdateAccount(ctx, accountA); err != nil {
return err // Failed to update account A balance
}
// Adding amount to account B balance
accountB.Balance += input.Amount
if err := s.Repo.UpdateAccount(ctx, accountB); err != nil {
return err // Failed to update account B balance
}
return nil
})
if txErr != nil {
return txErr
}
return nil
}
// Getting account by ID
func (r *repo) GetAccountByID(ctx context.Context, id uint) (model.AccountEntity, error) {
dbtx := ExtractTx(ctx, r.db) // extracting context and making regular db into DBTX interface
var account model.AccountModel
err := dbtx.QueryRow(ctx, "SELECT * FROM accounts WHERE id = $1", id).Scan(
/* ...scan fields of account... */ )
return account, err
}
// Updating account
func (r *repo) UpdateAccount(ctx context.Context, account model.AccountEntity) error {
dbtx := ExtractTx(ctx, r.db) // extracting context and making regular db into DBTX interface
_, err := dbtx.Exec(ctx, `
UPDATE accounts
SET balance = $1
WHERE id = $2`, account.Balance, account.ID)
return err
}
By implementing the above method, we successfully separate the logic layer from dependencies on third-party libraries. In the repository example I included, it can be seen that even to change ORMs, the service layer doesn’t need any changes. YEYY.
Let’s elaborate again, what are the advantages:
- Logic layer remains pure, not contaminated by gorm packages or other drivers.
- Database transactions can be controlled effectively, allowing to manage transaction scope to be kept as small as possible if needed. This approach is different from implementing transactions in middleware, which can cause the entire logic process to be within one database transaction.
- Code readability is maintained.
- Unit testing remains focused on business logic only.
Sample Github Repository
I include sample code in two versions, one for GORM and another for other implementations (pgx). Here, GORM is simpler because basically GORM has combined regular database operations with database transaction operations.
Here’s the repository: REPOSITORY
When implementing database transactions, it’s also important to consider the possibility of deadlocks. In the sample code I provided above, I have simplified the code by setting aside those aspects. I will discuss deadlocks further in future opportunities.