Pagination is a technique for dividing database query results into smaller chunks. Using LIMIT OFFSET queries is the most commonly used method. However, this method has several weaknesses, especially in terms of performance on very large datasets. This article will discuss problems that arise when using LIMIT OFFSET and explore more efficient alternatives, such as cursor-based pagination and seek method.
The Importance of Pagination and Its Challenges
Pagination has several benefits, such as:
Performance Maintenance: Returning large data all at once is slow and resource-intensive. By dividing data into smaller chunks, APIs can return data faster and with fewer resources. Processing large data also requires a lot of memory, which can be a problem for devices with limited resources like mobile phones. By using pagination, APIs can limit the amount of data that needs to be stored in memory at any given time.
User Experience: For client applications that display data to users, pagination can improve user experience by providing a faster and more responsive interface. Users can see initial results quickly and can request additional data as needed.
However, it’s important to remember that pagination is not always a perfect solution. On very large datasets, pagination techniques can face challenges that will become very fatal later on.
LIMIT OFFSET Pagination
Here we will discuss the disadvantages of pagination using LIMIT OFFSET and how to minimize these disadvantages.
Why is LIMIT OFFSET Slow for Large Datasets?
When dealing with very large datasets, pagination using LIMIT OFFSET often experiences performance degradation. This is because every time we request a new page, the database must scan the entire table from the beginning to find the appropriate data, even though we only need a small portion of the data.
Here’s an example SQL query showing how LIMIT and OFFSET are applied:
SELECT * FROM records
ORDER BY id
LIMIT 10 OFFSET 1000;
Explanation:
LIMIT determines the maximum number of rows returned.OFFSET determines how many rows to skip before starting to return results.
In the example above, the query will actually scan the first 1000 rows, discard unnecessary data, and return the next 10 rows. If the table has millions of rows, skipping a large number of rows with a large offset will make the query run slower because the database must sort and scan all those rows before returning results.
This means if the client makes requests for page 2, page 3 and so on, it will cause the database to process many times more data compared to the amount actually returned to the client.
As an illustration, assuming 1 page displays 100 data:
For page 1: OFFSET 0, LIMIT 100-> scans and returns 100 rows.For page 2: OFFSET 100, LIMIT 100-> scans and discards 100 rows, then scans and returns the next 100 rows.For page 3: OFFSET 200, LIMIT 100-> scans and discards 200 rows, then scans and returns the next 100 rows.For page 100: OFFSET 10000, LIMIT 100-> scans and discards 10000 rows, then scans and returns the next 100 rows.
The larger the offset value, the more rows need to be scanned and discarded, making the query slower and less efficient. This becomes very bad for tables with millions of rows because processing and discarding a lot of data every time there’s a new page request.
Worst case example for this: Client wants to get all data by scanning from page 1 to the last page. Looking at the behavior, this is usually needed by other services that use our service as their data source.
Imagine we want to read a very thick book page by page. If we use the LIMIT and OFFSET method, we have to open the book from the beginning every time we want to read the next page. This is certainly very inefficient, because we will repeatedly open the same pages. In the database context, this is the same as making the database work harder than it should. Therefore, if the goal is to get all data, it’s better to take the entire book (data) at once without pagination, then read it (process it) in the application.
Impact of COUNT(*) Query on Performance
Not only that, in pagination implementation using LIMIT and OFFSET, the SELECT COUNT(*) query is often used to count the total number of rows in the dataset. This information is needed to compile pagination metadata, such as total number of pages and total items, which is then returned in the API response.
For example, the API response might have a structure like this:
{
"message": "successfully fetch data",
"data": [
{}
],
"meta": {
"current_page": 1,
"page_size": 100,
"total_count": 3000,
"total_page": 30
},
"trace_id": "5b427ba9ab30002d347ea17cf8000cca"
}
To generate this metadata, the backend needs to perform two queries:
- To retrieve data with LIMIT and OFFSET
SELECT * FROM users LIMIT 100 OFFSET 0;
- To count the total number of rows with COUNT(*)
SELECT COUNT(*) FROM users;
Surprisingly, using COUNT(*) on large datasets can result in significant performance degradation. This is due to:
Full table scan: The database needs to scan the entire table to count the number of rows, especially if there are no suitable indexes.Lack of index optimization: COUNT(*) often cannot be optimized with indexes, so query execution time becomes longer.Concurrency and locking issues: COUNT(*) queries can cause locks with other queries and hinder system performance.High I/O load: The process of counting rows requires many read-write operations on the database disk.
This problem may not be clearly visible early in development, but will become more apparent as data volume continues to grow. Therefore, I highly recommend that we can determine the most suitable pagination technique from the beginning of development. Alternative techniques and optimizations can be good solutions to overcome them.
LIMIT OFFSET Database Query Optimization
It turns out that queries for pagination with LIMIT OFFSET can still be optimized. How to do it? I actually found this technique in a library used in another language, PHP Laravel. which can be found in this library: https://github.com/hammerstonedev/fast-paginate What is done to make the performance better?
select * from users -- The full data that you want to show your users.
where users.id in ( -- The "deferred join" or subquery, in our case.
select id from users -- The pagination, accessing as little data as possible - ID only.
limit 15 offset 150000
)
The idea is to apply LIMIT and OFFSET on data with a smaller scope, then search for the results to create complete data.
However, the SELECT COUNT(*) query may not be optimizable. So, this optimization technique on LIMIT OFFSET queries doesn’t completely solve the problems I experienced, especially for SELECT COUNT(*) queries on large datasets. This is evident from the monitoring results I conducted.

The monitoring results show a significant performance difference between query to retrieve data vs COUNT(*) query, especially when many requests come in simultaneously.
This is also supported by similar problems discussed on the internet such as:
- https://stackoverflow.com/questions/55018986/postgresql-select-count-query-takes-long-time
- https://www.reddit.com/r/PostgreSQL/comments/140b4xy/select_count_is_slow_in_large_tables/
- https://tunghatbh.medium.com/postgresql-slow-count-query-c93c30792606
From this case study, I draw several important conclusions:
Number of N queries doesn't always determine performance: It’s not always true that the fewer query requests we run, the better the performance. In some cases, splitting complex queries into several smaller queries can actually improve overall performance.Indexes are not always optimal for COUNT(*): Although indexes can improve query performance in general, in COUNT(*) cases indexes are not always effective.Importance of benchmarking: Comparing performance before and after query changes is the most accurate way to measure the impact of an optimization. Because different queries and data structures may require different optimization methods.
Cursor! As an Alternative to Limit Offset
Cursor-based Pagination Explanation
Cursor-based pagination uses a unique value from a column (usually the sorted column) as a “cursor” to mark the current position in the query results. Instead of using offset, we send the cursor from the previous result to get the next page. This is more efficient because the database can skip values and only needs to look for records that have cursor values greater than the previous cursor value.
SELECT * FROM users
WHERE sort_column > 'cursor_value'
ORDER BY sort_column
LIMIT 10;
Advantages of Cursor-based Pagination
Better performance: No need to scan the entire table for each page request.Consistent results: Query results are always the same, regardless of data changes that occur between requests. For example, pagination on LIMIT OFFSET will be inconsistent if data on previous pages is deleted.Infinity Loading UX: Cursor pagination is very suitable for web and mobile user experience that usually implements infinity loading.
Disadvantages of Cursor-based Pagination
More complex implementation: Requires careful planning in choosing the right cursor column.Not suitable for all types of queries and UX: Only effective for queries sorted by one or several columns.Stateful: Because it must pass the cursorSorting merged with cursor: The order of displayed data is always proportional to the cursor used.
Implementation Example
As an example, API response with cursor pagination might have a structure like this:
Endpoint: {baseURL}/users?limit=3&cursor=Query Param:limit: amount of data displayed.cursor: cursor input, for the first page fill in blank.cursor_type: what field is used as cursor, usually has a default value, in this example usinguliddescending.
{
"message": "successfully fetch data",
"data": [
{
"ulid": "01J4EXF94RZA4AZG1C0A0C2RKF",
"name": "muchlis"
},
{
"ulid": "01J4EXF94RWZVWS9NVEZMQ3R1N",
"name": "monkey d luffy"
},
{
"ulid": "01J4EXF94RT7G5CRH047MC0EF1",
"name": "portgas d ace"
}
],
"meta": {
"current_cursor": "",
"next_cursor": "01J4EXF94RT7G5CRH047MC0EF1",
"next_page": "/users?limit=3&cursor=01J4EXF94RT7G5CRH047MC0EF1",
"prev_cursor": "",
"prev_page": "/users?limit=3&cursor="
},
"trace_id": "5b427ba9ab30002d347ea17cf8000cca"
}
Repo Layer:
I use raw queries for easier readability. But in reality I usually use sql builders like golang squirrel or goqu.
func (r *repo) FetchUserByUlid(ctx context.Context, cursorID string, limit uint64) ([]entity.User, error) {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
var sqlStatement string
var args []interface{}
if cursorID != "" {
sqlStatement = `
SELECT id, name
FROM users
WHERE id < $1
ORDER BY id DESC
LIMIT $2;
`
args = append(args, cursorID, limit)
} else {
sqlStatement = `
SELECT id, name
FROM users
ORDER BY id DESC
LIMIT $1;
`
args = append(args, limit)
}
// Execute the query
rows, err := r.db.Query(ctx, sqlStatement, args...)
if err != nil {
return nil, fmt.Errorf("failed to execute query: %w", err)
}
defer rows.Close()
users := make([]entity.User, 0)
// [SKIP] Parse the results
// [SKIP] Check for errors after iterating over rows
return users, nil
}
Service Layer:
At the service layer, there is logic where we have to get more data than what will be displayed to know whether the next data exists or not.
func (s *Service) FetchAllUsersWithCursor(ctx context.Context, cursor string, limit uint64) ([]entity.User, *string /*next cursor*/, error) {
// [SKIP] validation, tracer etc
// Call repo layer to retrieve data
// Add Limit +1 so we know if there is continuation data or not
// This excess data will be discarded later
results, err := s.repo.FetchUserByUlid(ctx, cursor, limit+1)
if err != nil {
return nil, nil, fmt.Errorf("error FetchUserByUlid: %w", err)
}
// Determine next cursor
var nextCursor *string
if len(results) > int(limit) {
nextCursorID := results[limit-1].ID // Set cursor if more data than limit is found
nextCursor = &nextCursorID
results = results[:limit] // Remove excess data
} else {
nextCursor = nil // If there is no excess data, the next cursor is set to nil
}
// [SKIP] Convert results
return results, nextCursor, nil
}
Assuming using Clean Architecture or Hexagonal Architecture
+-------------------------------------+
| HTTP Handler |
| (Handling HTTP requests and |
| responses, routing, etc.) |
+----------------+--------------------+
|
v
+----------------+--------------------+
| Service |
| (Business logic, orchestrating the |
| application flow, validation, |
| calling Repositories) |
+----------------+--------------------+
|
v
+----------------+--------------------+
| Repository |
| (Data access layer, interacting with|
| the database, etc.) |
+-------------------------------------+
In the code example above, the remaining layer is the HTTP Handler which serves as the View, where that layer is responsible for creating other values from the service layer process results such as temporarily storing current_cursor, creating next_page values from the FetchAllUsersWithCursor() return value and various other values for responses that require the HTTP Handler Framework.
That was an example of a simplified cursor pagination implementation so we get a little picture of its complexity. Even in the code above I intentionally skipped several things below because they are optional.
- Previous_Page requires implementation that is the opposite of the default SQL Query. Instead of using cursor and order default
WHERE id < $1 ORDER BY id DESC, it becomesWHERE id > $1 ORDER BY id ASCwith cursor being the first value of the data displayed on the current page. - The possibility of cursors and orders that require 2 keys or even more.
- More strict value validation for Cursor and OrderBy types.
Benchmark:
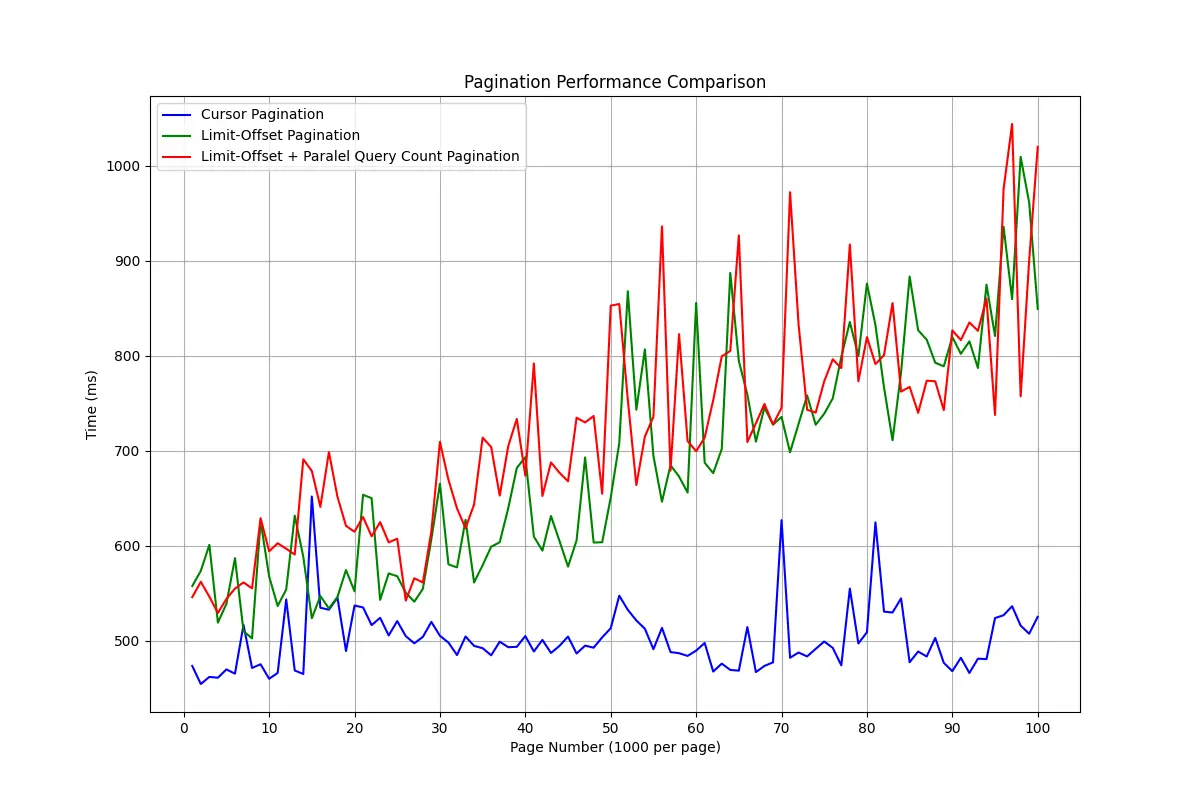
Analysis:
- Limit-Offset Pagination has response times that start to increase significantly after page 50 (meaning at data depth 50,000), showing poor scaling for large datasets.
- Limit-Offset + Query Count Pagination (run together with goroutine) Slightly slower than regular Limit-Offset, which shows additional overhead. The additional overhead from this count will be felt when requests are run in parallel. While the test above was done sequentially.
- Cursor Pagination is the most efficient and stable, suitable for large datasets with many pages.
Notes:
- This comparison compares all methods using uniform specifications and conditions. Network latency, structure and amount of data can affect results. So, just rely on the comparison, because the numbers will vary greatly depending on each condition.
- The data used includes 100,000 user data entries that are left-joined with 2 small tables with extreme pagination trials of 1,000 entries per page.
- Testing was done sequentially, page by page.
- This test does not include other factors that are actually important such as memory usage, CPU, rows computed in the database.
- Here I try to make minimal effort.
- Theoretically alone we can actually estimate which method is superior. This benchmark confirms that.
Limit-Offset Pagination has the advantage of ease of implementation, with weaknesses that will only be felt when our application reaches a level where the amount of data becomes very large. This weakness can also be overcome by providing indexed range and filtering predetermined data to users (such as when displaying bank transaction data that must determine the month).
On the other hand, although faster and more stable, Cursor-Based Pagination is slightly more complicated to implement and has certain limitations that may make it less suitable for all types of cases.
The saying premature optimization is the root of all evil reminds us that optimization that is too early can be a problem, but here in my personal opinion, avoiding mistakes from the start doesn’t mean it’s a bad thing either. In fact, making optimal architectural and design decisions, such as choosing Cursor-Based Pagination over Limit-Offset, can be considered a wise decision-making, not just premature optimization. Essentially, understanding the trade-offs of each choice and choosing the right solution for specific needs is a more appropriate approach in software development.