In Golang application development, we often find a single struct object used for various purposes, such as representing data in the database as well as payload in API requests and responses. Although this seems practical, this approach can actually create problems related to security and maintenance. This article will discuss the importance of separating DTO, Entity and Model by applying some Domain-Driven Design (DDD) principles.
Understanding Entity, Model and DTO in Domain-Driven Design Principles
Domain-Driven Design (DDD) is a software development methodology that focuses on separation of responsibilities through modeling oriented towards business domains. In DDD, we recognize several important concepts:
- Data Transfer Object (DTO): Used to transfer data between functions without involving complex business logic. For example, structs for requests, responses, and function parameters.
- Entity: Used to store data that will be used in application logic. A struct is called an entity if it has an identity (such as an ID) that distinguishes it from other data. Entities can have their own logic. For example, a Weather entity that has an
IsOutdoorEventFeasible()method to evaluate whether the weather is suitable for outdoor events.type WeatherEntity struct { ID string // example: Combination of Location Code and Timestamp City string Temperature float64 Humidity int Description string } // IsOutdoorEventFeasible evaluates whether the weather is suitable for outdoor events. func (w *WeatherEntity) IsOutdoorEventFeasible() bool { // outdoor events are considered not feasible if: // - Temperature below 15 degrees Celsius or above 35 degrees Celsius // - Weather description indicates rain or storm if w.Temperature < 15 || w.Temperature > 35 { return false } if w.Description == "rain" || w.Description == "storm" { return false } return true } - Repository: Repository objects hide data storage implementation details. While Model structs function as data representation in the database used by Repository.
- Application Service: Handles business logic that requires interaction with external components or other services, in clean architecture this is often called
usecaseorservice. Handles operations that don’t naturally fit within the context of Entity or Value Object.
Actually there are many others, such as Value Object, Aggregate, Domain-Service etc.
However, we want our code to be “good-enough for maintainability”, but also “not become too complex”, so here we are a bit loose in applying DDD.
Why is Separation Important?
Using the same struct across different application layers like database, business logic, and presentation can create high coupling. For example, changes in the database (such as adding new columns) can affect the API, even if those columns are not relevant for API users.
Scenario
Suppose we have an application that helps users plan events based on weather forecasts. Our application uses a third-party weather API to get current weather information.
type Weather struct {
City string `json:"city" db:"city"`
Temperature float64 `json:"temperature" db:"temperature"`
Humidity int `json:"humidity" db:"humidity"`
WindSpeed float64 `json:"wind_speed" db:"wind_speed"`
Description string `json:"description" db:"description"`
}
One day, the third-party weather API announces changes to their response, adding more details like airQualityIndex, visibility, and uvIndex. They even make major changes to version 2 such as splitting temperature into temperature_celsius and temperature_kelvin.
Impact Without Struct Separation (bad)
If we use the same Weather struct to capture responses from the API, store data in the database, and also as our API response, changes in the third-party API can cause several problems:
- Changes in Many Places: Changes in one struct means also changing the database, business logic, and possibly also data consumed by the frontend.
- Overfetching and Irrelevant Data: we might not need all the additional data like temperature_kelvin or uvIndex for our application’s purposes, but because we use the same structure, we are forced to handle this extra data.
- Increased Complexity: With new data, we might need some modifications to the data types to adjust Tags, Marshalers, Scanners and Valuers.
Impact With Struct Separation (good)
Conversely, by separating DTO, Entity, and Model, we can more efficiently handle these changes.
DTO (Data Transfer Object):
We create a dedicated struct to capture responses from the weather API that includes all new data (or only relevant data).
Helps us to know data availability from the API.
For the above scenario, we only need to adjust the API Client layer.
type WeatherAPIResponse struct {
City string `json:"city"`
TemperatureCelsius float64 `json:"temperature_celsius"`
TemperatureKelvin float64 `json:"temperature_kelvin"`
Humidity int `json:"humidity"`
WindSpeed float64 `json:"wind_speed"`
Description string `json:"description"`
AirQualityIndex int `json:"airQualityIndex"`
Visibility int `json:"visibility"`
UvIndex int `json:"uvIndex"`
}
func (w *WeatherAPIResponse) ToEntity(){
// transform
}
Entity:
The Weather entity in our application only stores data relevant to the application’s function, such as Temperature, Humidity, and Description. No need to store uvIndex or visibility if that data is not used in the event planning process, so we know which data is important for logic and which is not.
type WeatherEntity struct {
ID string // Combination of Location Code and Timestamp
City string
Temperature float64
Humidity int
Description string
}
// IsOutdoorEventFeasible evaluates whether the weather is suitable for outdoor events.
func (w *WeatherEntity) IsOutdoorEventFeasible() bool {
// outdoor events are considered not feasible if:
// - Temperature below 15 degrees Celsius or above 35 degrees Celsius
// - Weather description indicates rain or storm
if w.Temperature < 15 || w.Temperature > 35 {
return false
}
if w.Description == "rain" || w.Description == "storm" {
return false
}
return true
}
Business Logic (Usecase Layer):
Business logic should not know about database models or responses from third-party APIs. Business logic only processes data that is already in Entity form or that we can control its stability. This facilitates maintenance and reduces the risk of errors.
Database Model:
For database storage purposes, use a separate struct, especially if using ORM
type WeatherModel struct {
ID string `db:"id"`
City string `db:"city"`
Temperature float64 `db:"temperature"`
Humidity int `db:"humidity"`
Description string `db:"description"`
}
func (w *WeatherModel) ToEntity(){
// transform
}
func FromEntity(WeatherEntity) WeatherModel {
// transform
}
and so on for WeatherRequestDTO and WeatherResponseDTO.
Trade-offs
Although separating data structures like DTO (Data Transfer Object), Entity, and database Model has long-term benefits such as security, ease in testing, and clear separation of concerns, there are some drawbacks that need to be considered as well. One of the main drawbacks is the need to perform transformations between these structs, which means there is a slight sacrifice in speed.
However, this approach is often considered a reasonable price for the benefits gained. Popular books like Clean Code by Robert C. Martin, The Pragmatic Programmer by Andrew Hunt and David Thomas, and Refactoring: Improving the Design of Existing Code by Martin Fowler, often emphasize the importance of prioritizing correct and maintainable code before focusing on speed.
Besides, the latency generated from this data transformation is very very very minimal compared to the latency of database operations, which tend to be a more significant bottleneck in many applications.
When Should You NOT Separate Structs?
- The system is too simple.
- Requires high speed such as in game development.
- The slightest performance improvement is considered more important than readability and ease of maintenance.
How to Properly Separate Structs
I recommend the following approach to separate golang structs in API architecture. This approach ensures that each layer in the application has clear and separate responsibilities, making maintenance and future development easier.
Structs for Presentation Layer:
- WeatherRequest and WeatherResponse: These structs are used to handle data coming in and out of the API (presentation). They are responsible for validating and formatting data according to client needs.
- For more complex cases, such as partial update features, you might need WeatherUpdateRequest. This version uses pointer fields to allow partial updates.
Structs for Domain Layer:
- WeatherEntity: This entity represents data in the business domain and contains logic directly related to business rules. Entities should be stable and not affected by changes in other layers, such as databases or external APIs.
- For more complex cases, such as partial update features, you might need WeatherUpdateDTO. A DTO version that also uses pointer fields for flexibility in data transmission.
Structs for Persistence Layer:
- WeatherModel: This struct is used for database interaction. This model reflects the storage schema and can change along with changes in the database layer.
Implementation Diagram
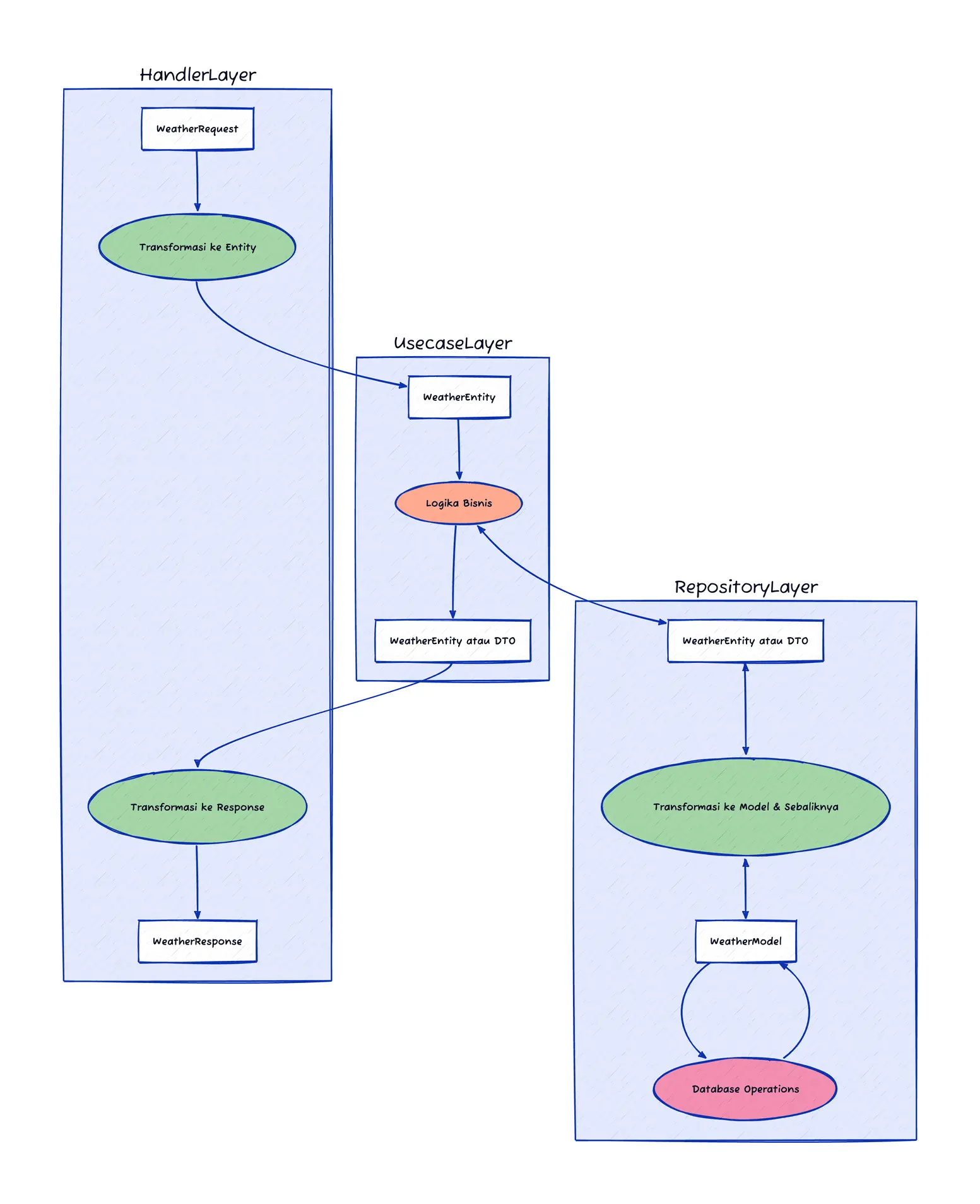
Assuming using Clean Architecture or Hexagonal Architecture, then:
- Handler Layer manages request and response data, converts requests to internal data types that we can fully control (entity) before passing to Usecase.
- Usecase Layer works with stable entities, this layer should avoid direct dependencies on database models or external API formats.
- Repository Layer manages database access and converts data to and from entities used by usecase.
This approach ensures that each layer is isolated from irrelevant changes in other layers, thereby improving application resilience and flexibility. By separating responsibilities in each layer, applications become more modular, facilitating maintenance and scalability.
Also read: How to apply good rules to maintain separation of concerns
Conclusion
Implementing separation of DTO, Entity and Model structs in API design using Golang is a small investment that can save a lot of time and resources for development and maintenance in the future, making our system not only efficient but also easy to manage and develop. This approach can clearly divide the responsibilities of each component, reduce dependencies between modules, and ultimately strengthen the overall application architecture itself.
Of course, there is no one perfect approach for every situation. How has your experience been in implementing or perhaps not implementing this principle? Are there specific cases where you found more effective alternatives? Share your experience in the comments section!