Pagination adalah teknik dalam membagi hasil query database menjadi bagian-bagian yang lebih kecil. Menggunakan Query LIMIT OFFSET adalah metode yang paling umum digunakan. Namun, metode ini ternyata memiliki beberapa kelemahan, terutama dalam hal performa pada dataset yang sangat besar. Artikel ini akan membahas masalah-masalah yang akan muncul saat menggunakan LIMIT OFFSET dan mengeksplorasi alternatif yang lebih efisien, seperti cursor-based pagination dan seek method.
Pentingnya Pagination dan Tantangannya
Pagination memiliki beberapa manfaat, seperti:
Menjaga Performance: Mengembalikan data yang besar sekaligus itu lambat dan memakan banyak sumber daya. Dengan membagi data menjadi potongan-potongan yang lebih kecil, API bisa mengembalikan data lebih cepat dan dengan sumber daya yang lebih sedikit. Memproses data yang besar juga memerlukan banyak memori, yang bisa menjadi masalah untuk perangkat dengan sumber daya terbatas seperti ponsel. Dengan menggunakan pagination, API dapat membatasi jumlah data yang perlu disimpan dalam memori pada suatu waktu.
User Experience: Untuk aplikasi klien yang menampilkan data kepada user, pagination dapat meningkatkan pengalaman user dengan menyediakan antarmuka yang lebih cepat dan responsif. User dapat melihat hasil awal dengan cepat dan dapat meminta data tambahan sesuai kebutuhan.
Namun, penting untuk diingat bahwa pagination tidak selalu menjadi solusi yang sempurna. Pada dataset yang sangat besar, teknik pagination dapat menghadapi tantangan yang akan menjadi sangat fatal dikemudian hari.
LIMIT OFFSET Pagination
Disini kita akan bahas kekurangan dari cara pagination menggunakan LIMIT OFFSET dan bagaimana cara meminimalisir kekurangan tersebut.
Mengapa LIMIT OFFSET Lambat untuk Dataset yang Besar?
Saat berhadapan dengan dataset yang sangat besar, pagination menggunakan LIMIT OFFSET seringkali mengalami penurunan performa. Ini karena setiap kali kita meminta halaman baru, database harus memindai seluruh tabel dari awal untuk menemukan data yang sesuai, meskipun kita hanya membutuhkan sebagian kecil data.
Berikut adalah contoh query SQL yang menunjukkan bagaimana LIMIT dan OFFSET diterapkan:
SELECT * FROM records
ORDER BY id
LIMIT 10 OFFSET 1000;
Penjelasan:
LIMIT menentukan jumlah maksimal baris yang dikembalikan.OFFSET menentukan berapa banyak baris yang harus skip sebelum mulai mengembalikan hasil.
Pada contoh di atas, query tersebut sebenarnya akan memindai 1000 baris pertama, membuang data yang tidak diperlukan, dan mengembalikan 10 baris berikutnya. Jika tabel memiliki jutaan baris, melewati sejumlah besar baris dengan offset yang besar akan membuat query berjalan lebih lambat karena database harus mengurutkan dan memindai semua baris tersebut sebelum mengembalikan hasil.
Artinya jika klien melakukan permintaaan page 2, page 3 dan seterusnya maka akan menyebabkan database harus memproses berkali-kali lipat data dibandingkan dengan jumlah yang sebenarnya dikembalikan kepada klien.
Sebagai ilustrasi, asumsi jika 1 halaman menampilkan 100 data:
Untuk page 1: OFFSET 0, LIMIT 100-> memindai dan mengembalikan 100 baris.Untuk page 2: OFFSET 100, LIMIT 100-> memindai dan membuang 100 baris, kemudian memindai dan mengembalikan 100 baris berikutnya.Untuk page 3: OFFSET 200, LIMIT 100-> memindai dan membuang 200 baris, kemudian memindai dan mengembalikan 100 baris berikutnya.Untuk page 100: OFFSET 10000, LIMIT 100-> memindai dan membuang 10000 baris, kemudian memindai dan mengembalikan 100 baris berikutnya.
Semakin besar nilai offset, semakin banyak baris yang perlu dipindai dan dibuang, yang membuat query semakin lambat dan tidak efisien. Ini menjadi sangat buruk untuk tabel dengan jutaan baris karena memproses dan membuang banyak data setiap kali ada permintaan halaman baru.
Contoh worst case untuk ini : Client ingin mendapatkan semua data dengan cara melakukan scan dari page 1 sampai dengan page terakhir. Melihat behaviornya, hal ini biasanya diperlukan oleh service lain yang menjadikan service kita sebagai data sourcenya.
Bayangkan kita ingin membaca sebuah buku yang sangat tebal halaman demi halaman. Jika kita menggunakan metode LIMIT dan OFFSET, kita harus membuka buku dari awal setiap kali ingin membaca halaman berikutnya. Ini tentu sangat tidak efisien, karena kita akan mengulang-ulang membuka halaman yang sama. Dalam konteks database, hal ini sama dengan membuat database bekerja lebih keras dari yang seharusnya. Oleh karena itu, jika tujuannya adalah mendapatkan semua data, lebih baik kita langsung mengambil seluruh buku (data) sekaligus tanpa pagination, lalu membacanya (memprosesnya) di aplikasi.
Dampak Query COUNT(*) terhadap Performa
Tidak hanya itu, dalam implementasi pagination menggunakan LIMIT dan OFFSET, query SELECT COUNT(*) sering digunakan untuk menghitung jumlah total baris dalam dataset. Informasi ini diperlukan untuk menyusun metadata pagination, seperti jumlah total halaman dan jumlah total item, yang kemudian dikembalikan dalam respon API.
Sebagai contoh, respon API mungkin memiliki struktur sebagai berikut:
{
"message": "successfully fetch data",
"data": [
{}
],
"meta": {
"current_page": 1,
"page_size": 100,
"total_count": 3000,
"total_page": 30
},
"trace_id": "5b427ba9ab30002d347ea17cf8000cca"
}
Untuk menghasilkan metadata ini, backend perlu melakukan dua query:
- Untuk mengambil data dengan LIMIT dan OFFSET
SELECT * FROM users LIMIT 100 OFFSET 0;
- Untuk menghitung jumlah total baris dengan COUNT(*)
SELECT COUNT(*) FROM users;
Kejutannya, Penggunaan COUNT(*) pada dataset yang besar dapat mengakibatkan penurunan performa yang signifikan. Hal ini dikarenakan:
Full table scan: Database perlu memindai seluruh tabel untuk menghitung jumlah baris, terutama jika tidak ada indeks yang sesuai.Kurangnya optimasi indeks: COUNT(*) seringkali tidak dapat dioptimalkan dengan indeks, sehingga waktu eksekusi query menjadi lebih lama.Masalah concurency dan locking: Query COUNT(*) dapat menyebabkan lock dengan query lain dan menghambat kinerja sistem.Beban I/O yang tinggi: Proses penghitungan jumlah baris memerlukan banyak operasi baca-tulis pada disk database.
Masalah ini mungkin tidak terlihat jelas pada awal pengembangan, tetapi akan semakin terasa ketika volume data terus bertambah. Maka dari itu saya sangat merekomendasikan agar kita dapat menentukannya teknik pagination yang paling sesuai sejak awal pengembangan. Teknik alternatif dan optimasi dapat menjadi solusi yang baik untuk mengatasinya.
Optimasi Database Query LIMIT OFFSET
Ternyata query untuk pagination dengan LIMIT OFFSET masih dapat dioptimalkan. Bagaimana caranya ? Teknik ini justru saya temukan di library yang digunakan pada bahasa lain, PHP Laravel. yang dapat dicontoh pada library ini : https://github.com/hammerstonedev/fast-paginate Apa yang dilakukan untuk membuat peformanya menjadi lebih baik ?
select * from users -- The full data that you want to show your users.
where users.id in ( -- The "deferred join" or subquery, in our case.
select id from users -- The pagination, accessing as little data as possible - ID only.
limit 15 offset 150000
)
Idenya adalah agar melakukan penerapan LIMIT dan OFFSET pada data yang scopenya lebih kecil, baru kemudian hasilnya dicari untuk membuat data yang lengkap.
Namun query SELECT COUNT(*) belum tentu dapat dioptimalkan. Jadi, teknik optimasi pada query LIMIT OFFSET ini tidak sepenuhnya menyelesaikan masalah yang saya alami, terutama untuk query SELECT COUNT(*) pada dataset besar. Hal ini terlihat pada hasil monitoring yang saya lakukan.

Hasil monitoring menunjukkan perbedaan kinerja yang signifikan antara query untuk mengambil data vs query COUNT(*), Khususnya ketika banyak request yang masuk secara bersamaan.
Hal ini juga didukung oleh problem-problem serupa yang dibahas di internet seperti :
- https://stackoverflow.com/questions/55018986/postgresql-select-count-query-takes-long-time
- https://www.reddit.com/r/PostgreSQL/comments/140b4xy/select_count_is_slow_in_large_tables/
- https://tunghatbh.medium.com/postgresql-slow-count-query-c93c30792606
Dari studi kasus ini, saya menarik beberapa kesimpulan penting:
Jumlah N query tidak selalu menentukan kinerja: Tidak selalu benar bahwa semakin sedikit jumlah permintaan query yang kita jalankan, semakin baik performanya. Dalam beberapa kasus, membagi query kompleks menjadi beberapa query yang lebih kecil justru dapat meningkatkan kinerja secara keseluruhan.Indeks tidak selalu optimal untuk COUNT(*): Meskipun indeks dapat meningkatkan kinerja query secara umum, pada kasus COUNT(*) indeks tidak selalu efektif.Pentingnya benchmarking: Membandingkan kinerja sebelum dan sesudah perubahan query adalah cara yang paling akurat untuk mengukur dampak dari suatu optimasi. Karena beda query dan struktur datanya, bisa jadi memerlukan cara optimasi yang berbeda pula.
Cursor ! Sebagai Alternatif dari Limit Offset
Penjelasan Cursor-based Pagination
Cursor-based pagination menggunakan nilai unik dari suatu kolom (biasanya kolom yang diurutkan) sebagai “cursor” untuk menandai posisi saat ini dalam hasil query. Alih-alih menggunakan offset, kita mengirimkan cursor dari hasil sebelumnya untuk mendapatkan halaman berikutnya. Ini lebih efisien karena database dapat melompati nilai dan hanya perlu mencari rekaman yang memiliki nilai cursor lebih besar dari nilai cursor sebelumnya.
SELECT * FROM users
WHERE sort_column > 'cursor_value'
ORDER BY sort_column
LIMIT 10;
Kelebihan Cursor-based Pagination
Performa lebih baik: Tidak perlu memindai seluruh tabel untuk setiap permintaan halaman.Hasil yang konsisten: Hasil query selalu sama, terlepas dari perubahan data yang terjadi di antara permintaan. Misalnya pagination pada LIMIT OFFSET akan tidak konsisten jika data pada halaman sebelumnya ada yang dihapus.UX infinity Loading: Cursor pagination sangat cocok untuk user experience web dan mobile yang biasanya menerapkan infinity loading.
Kekurangan Cursor-based Pagination
Implementasi lebih kompleks: Membutuhkan perencanaan yang matang dalam memilih kolom cursor yang tepat.Tidak cocok untuk semua jenis query dan UX: Hanya efektif untuk query yang diurutkan berdasarkan satu atau beberapa kolom.Statefull: Karna harus meneruskan cursorSorting menyatu dengan cursor: Bahwa urutan data yang ditampilkan selalu berbanding lurus dengan cursor yang digunakan.
Contoh Implementasi
Sebagai contoh, respon API dengan cursor pagination mungkin memiliki struktur sebagai berikut:
Endpoint: {baseURL}/users?limit=3&cursor=Query Param:limit: jumlah data yang ditampilkan.cursor: inputan cursor, untuk halaman pertama di isi kosong.cursor_type: field apa yang dijadikan cursor, biasanya memiliki default value, dalam contoh ini menggunakanuliddescending.
{
"message": "successfully fetch data",
"data": [
{
"ulid": "01J4EXF94RZA4AZG1C0A0C2RKF",
"name": "muchlis"
},
{
"ulid": "01J4EXF94RWZVWS9NVEZMQ3R1N",
"name": "monkey d luffy"
},
{
"ulid": "01J4EXF94RT7G5CRH047MC0EF1",
"name": "portgas d ace"
}
],
"meta": {
"current_cursor": "",
"next_cursor": "01J4EXF94RT7G5CRH047MC0EF1",
"next_page": "/users?limit=3&cursor=01J4EXF94RT7G5CRH047MC0EF1",
"prev_cursor": "",
"prev_page": "/users?limit=3&cursor="
},
"trace_id": "5b427ba9ab30002d347ea17cf8000cca"
}
Repo Layer :
Saya menggunakan raw query demi keterbacaan yang lebih mudah. Namun di kenyataan saya bisanya menggunakan sql builder seperti golang squirell atau goqu.
func (r *repo) FetchUserByUlid(ctx context.Context, cursorID string, limit uint64) ([]entity.User, error) {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
var sqlStatement string
var args []interface{}
if cursorID != "" {
sqlStatement = `
SELECT id, name
FROM users
WHERE id < $1
ORDER BY id DESC
LIMIT $2;
`
args = append(args, cursorID, limit)
} else {
sqlStatement = `
SELECT id, name
FROM users
ORDER BY id DESC
LIMIT $1;
`
args = append(args, limit)
}
// Execute the query
rows, err := r.db.Query(ctx, sqlStatement, args...)
if err != nil {
return nil, fmt.Errorf("failed to execute query: %w", err)
}
defer rows.Close()
users := make([]entity.User, 0)
// [SKIP] Parse the results
// [SKIP] Check for errors after iterating over rows
return users, nil
}
Service Layer :
Pada service layer, terdapat logic dimana kita harus mendapatkan data lebih daripada yang akan ditampilkan untuk mengetahui apakah data selanjutnya itu ada atau tidak.
func (s *Service) FetchAllUsersWithCursor(ctx context.Context, cursor string, limit uint64) ([]entity.User, *string /*next cursor*/, error) {
// [SKIP] validation, tracer dan sebagainya
// Panggil repo layer untuk mengambil data
// Menambahkan Limit +1 sehingga kita tau ada data lanjutan atau tidak
// Data berlebih ini akan dibuang kemudian
results, err := s.repo.FetchUserByUlid(ctx, cursor, limit+1)
if err != nil {
return nil, nil, fmt.Errorf("error FetchUserByUlid: %w", err)
}
// Menentukan cursor selanjutnya
var nextCursor *string
if len(results) > int(limit) {
nextCursorID := results[limit-1].ID // Set cursor apabila ditemukan data lebih dari limit
nextCursor = &nextCursorID
results = results[:limit] // Hapus data yang kelebihan
} else {
nextCursor = nil // Jika tidak ada kelebihan data, cursor selanjutnya diset nil
}
// [SKIP] Konversi hasil
return results, nextCursor, nil
}
Dengan asumsi menggunakan Clean Architecture atau Hexagonal Architecture
+-------------------------------------+
| HTTP Handler |
| (Handling HTTP requests and |
| responses, routing, etc.) |
+----------------+--------------------+
|
v
+----------------+--------------------+
| Service |
| (Business logic, orchestrating the |
| application flow, validation, |
| calling Repositories) |
+----------------+--------------------+
|
v
+----------------+--------------------+
| Repository |
| (Data access layer, interacting with|
| the database, etc.) |
+-------------------------------------+
Pada contoh code di atas tersisa layer HTTP Handler yang bertugas sebagai View, dimana layer tersebut yang bertanggung jawab membuat value-value lain hasil dari proses layer service seperti menyimpan sementara current_cursor, membuat nilai next_page dari return value FetchAllUsersWithCursor() dan berbagai value lain untuk response yang memerlukan Framework HTTP Handler.
Tadi adalah contoh implementasi cursor pagination yang disederhanakan sehingga kita mendapatkan sedikit gambaran tentang kerumitannya. Pun pada code diatas saya sengaja melewatkan beberapa hal berikut karena bersifat optional.
- Previous_Page memerlukan implementasi yang berkebalikan pada Query SQL. Alih alih menggunakan cursor dan order default
WHERE id < $1 ORDER BY id DESC, menjadiWHERE id > $1 ORDER BY id ASCdengan cursor adalah value pertama dari data yang ditampilkan pada current page. - Adanya kemungkinan cursor dan urutan yang memerlukan 2 key bahkan lebih.
- Validasi value yang lebih ketat untuk tipe Cursor dan OrderBy.
Benchmark :
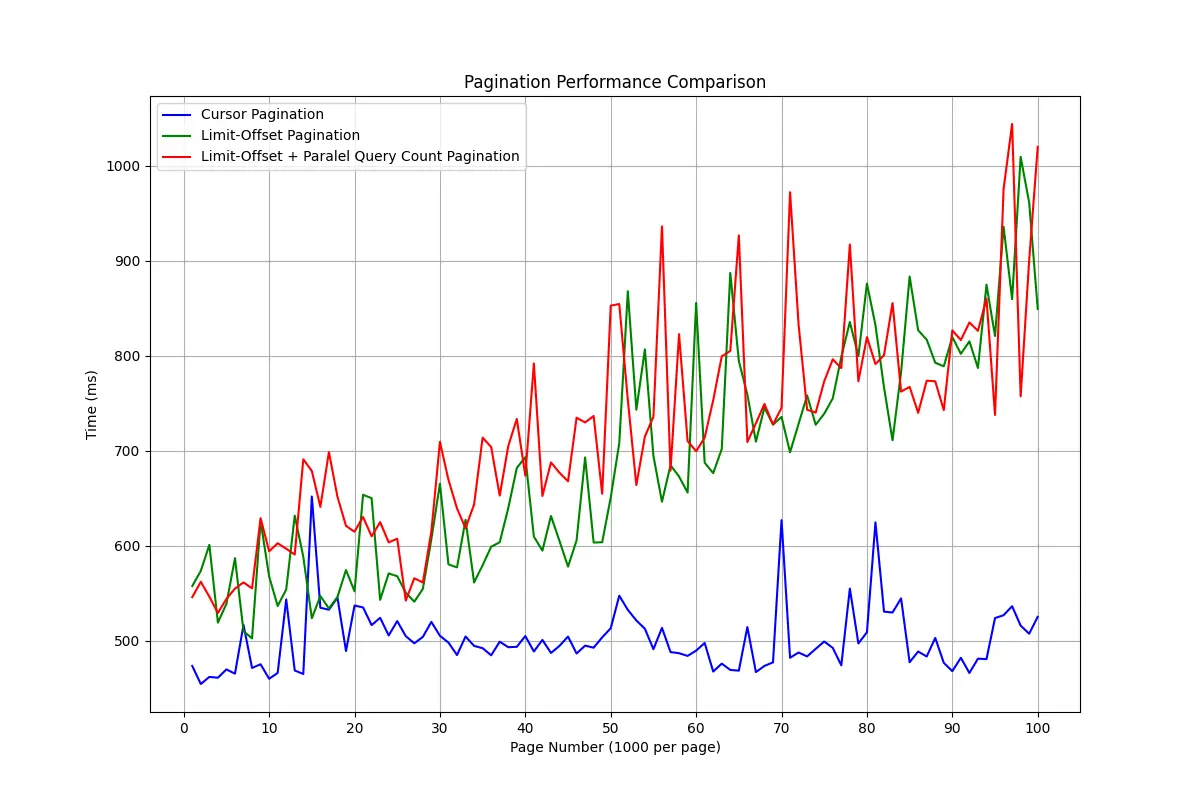
Analisis:
- Limit-Offset Pagination memiliki waktu respon yang mulai meningkat signifikan setelah halaman ke-50 (artinya di kedalaman data 50_000), menunjukkan skala yang buruk untuk dataset besar.
- Limit-Offset + Query Count Pagination (dijalankan bersamaan dengan goroutine) Sedikit lebih lambat dari Limit-Offset biasa, yang menunjukkan adanya overhead tambahan. Overhead tambahan dari count ini akan terasa ketika request dijalankan secara paralel. Sedangkan pengujian diatas dilakukan secara sequensial.
- Cursor Pagination paling efisien dan stabil, cocok untuk dataset besar dengan jumlah halaman yang banyak.
Catatan :
- Komparasi ini membandingkan semua metode menggunakan spesifikasi dan kondisi yang seragam. Latensi jaringan, struktur dan jumlah data dapat mempengaruhi hasil. Jadi, cukup berpatokan pada perbandingannya saja, karena angkanya akan sangat bervariasi tergantung kondisi masing-masing.
- Data yang digunakan mencakup 100_000 entri data user yang di left-join kan dengan 2 table kecil dengan percobaan pagination ekstrem pada 1_000 entri per halaman.
- Pengujian dilakukan secara sequensial, page per page.
- Pengujian ini tidak menyertakan faktor lain yang sebenarnya penting seperti penggunaan memori, CPU, Row yang dikomputasi pada database.
- Disini saya berusaha membuat effort seminimal mungkin.
- Secara teori saja sebenarnya kita dapat memperkirakan metode mana yang lebih unggul. Benchmark ini mengonfirmasi hal tersebut.
Limit-Offset Pagination memiliki keunggulan berupa kemudahan implementasi, dengan kelemahan yang hanya akan dirasakan ketika aplikasi kita mencapai level dimana jumlah data menjadi sangat besar. Kelemahan ini juga bisa diatasi dengan cara memberikan indexed range dan filtering data yang sudah ditentukan kepada user (seperti saat menampilkan data transaksi bank yang wajib menentukan bulannya).
Di sisi lain, walaupun lebih cepat dan stabil, Cursor-Based Pagination sedikit lebih rumit untuk diimplementasikan dan memiliki keterbatasan tertentu yang mungkin membuatnya kurang cocok untuk semua jenis kasus.
Pepatah premature optimization is the root of all evil mengingatkan kita bahwa optimasi yang terlalu dini bisa menjadi masalah, namun disini menurut saya pribadi, menghindari kesalahan sejak awal bukan berarti hal yang buruk juga. Justru, mengambil keputusan arsitektur dan desain yang optimal, seperti memilih Cursor-Based Pagination daripada Limit-Offset, dapat dianggap sebagai pengambilan keputusan yang bijak, bukan sekadar premature optimization. Pada intinya, memahami trade-off dari setiap pilihan dan memilih solusi yang tepat untuk kebutuhan spesifik adalah pendekatan yang lebih tepat dalam pengembangan perangkat lunak.