Profiling adalah proses mengukur kinerja aplikasi untuk mengidentifikasi dan menganalisis berbagai aspek yang mempengaruhi performa, seperti penggunaan CPU, memori, dan goroutine. Profiling sangat penting dalam proses pengembangan untuk memastikan aplikasi berjalan efisien dan optimal serta untuk mendeteksi anomali.
Tujuan Profiling pada artikel ini
- Mendeteksi kebocoran memori (memory leak).
- Mengetahui kode yang berjalan lambat.
- Mengoptimasi kode.
Output profiling di golang contohnya seperti ini :
Persiapan
Modifikasi Kode
Untuk dapat melakukan profiling yang dibutuhkan adalah mengimpor package
net/http/pprofagar service kita dapat menjalankan dan mengekspose endpoint/debug/pprof. Namun, alih alih menggunakan server HTTP utama, lebih baik jika endpoint khusus debug tersebut diekspos secara terpisah agar tidak ada kebocoran data yang tidak semestinya.Implementasinya seperti contoh dibawah ini:
package main import ( "net/http" "net/http/pprof" ) func debugMux() *http.ServeMux { mux := http.NewServeMux() // Register all the standard library debug endpoints. mux.HandleFunc("/debug/pprof/", pprof.Index) mux.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline) mux.HandleFunc("/debug/pprof/profile", pprof.Profile) mux.HandleFunc("/debug/pprof/symbol", pprof.Symbol) mux.HandleFunc("/debug/pprof/trace", pprof.Trace) return mux }func main() { config := cfg.Load() ctx := context.Background() debugPort := 4000 serverPort := 8080 // start debug server in other goroutine menggunakan port 4000 debugMux := debugMux() go func(mux *http.ServeMux) { if err := http.ListenAndServe(fmt.Sprintf("0.0.0.0:%v", debugPort), mux); err != nil { log.Error("serve debug api", err) } }(debugMux) // start main server in main goroutine menggunakan port 8080 webApi := web.New(app.logger, serverPort, config.App.Env, config.App.Name) err = webApi.Serve(app.routes()) if err != nil { log.Error("serve web api", err) } }pada contoh diatas, kita menjalankan dua server HTTP. yaitu port 4000 untuk debug/profiling dan 8080 untuk program utama.
Mengujicoba Endpoint Debug.
ketika server dijalankan, melakukan hit ke endpoint
http://localhost:4000/debug/pprof/akan menampilkan halaman web seperti berikut :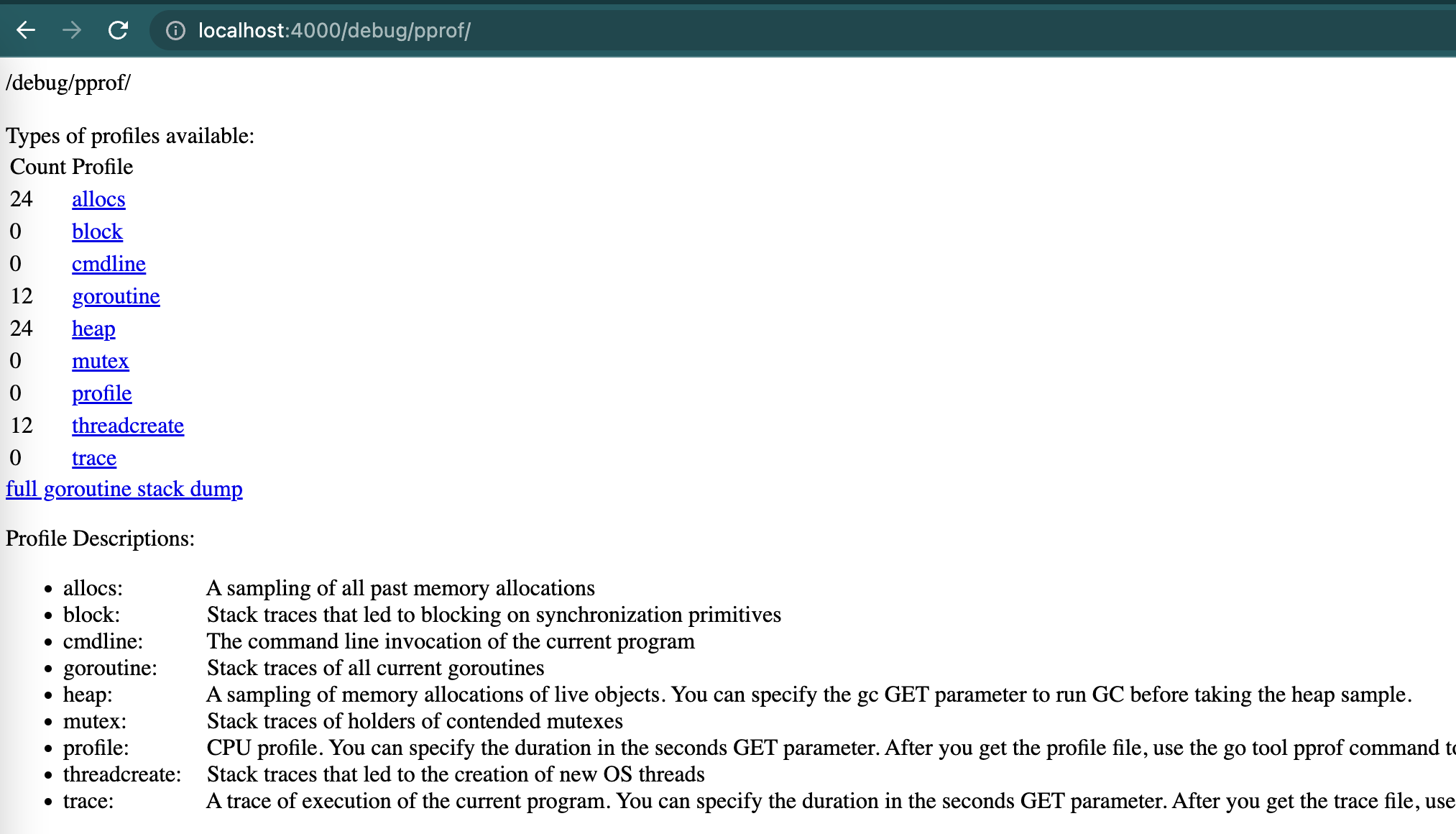
Pada halaman ini, kita dapat mengetahui keuntungan apa saja dan data apa saja yang bisa kita analisa dari endpoint ini.
Pada umumnya yang digunakan adalah
- allocs : untuk menganalisa memory berdasarkan sample
- heap: untuk menganalisa memory pada program yang sedang berjalan
- profile: untuk menganalisa penggunaan CPU.
Requirement Tools.
Untuk menganalisa, kita menggunakan
pprofyang bisa dijalankan dengan perintahgo tool pprof <file/url>Tools tambahan lainnya adalah Graphviz (untuk membuat grafik)
# ubuntu apt-get install graphviz gv # mac brew install graphviz
Cara melakukan Memory Profiling
Mendapatkan Sample Data Heap/Allocs. Perintah dibawah akan menghasilkan sebuah file bernama
heap.out:curl -s -v http://localhost:4000/debug/pprof/heap > heap.outMulai Analisa File Tadi dengan pprof
go tool pprof heap.outPerintah yang biasa digunakan:
- top : untuk menampilkan data teratas penggunaan memory teratas.
- top50 : untuk menampilkan hasil teratas sesuai jumlah angka (Top n).
- top -cum : untuk menampilkan data teratas dengan urutan memori kumulatif.
- png : untuk menampilkan visualisasi data profiling menjadi gambar dengan format png.
- web: untuk menampilkan visualisasi melalui browser
- list
: untuk menganalisa nama fungsi secara lebih detail.
Hint:
flatmenunjukkan jumlah memori atau waktu CPU yang dihabiskan oleh fungsi tersebut secara langsung, bukan oleh fungsi yang dipanggil olehnya.cum (cumulative)menunjukkan jumlah total memori atau waktu CPU yang dihabiskan oleh fungsi tersebut dan semua fungsi yang dipanggil olehnya (secara rekursif).
Umumnya semua penggunaan memory bisa terlihat dengan perintah
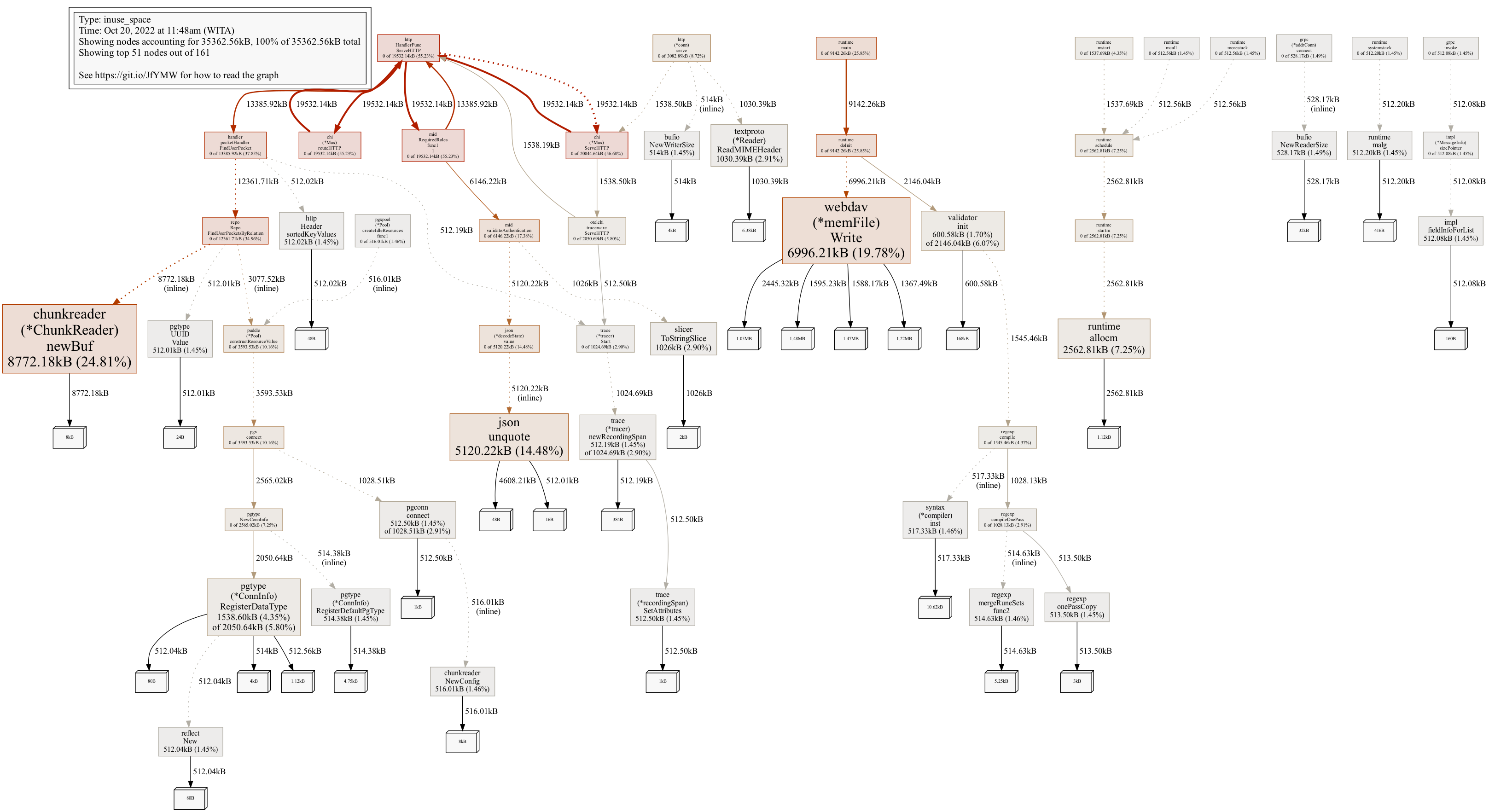
pngatauwebyang akan menampilkan grafik seperti berikut ini. Gambar dibawah ini adalah penggunaan yang cukup normal. Jika terjadi memory leak kita bisa dengan mudah melihat kotak besar yang sangat mencolok yang dari waktu kewaktu akan terus membesar :untuk lebih detail, gunakan pprof menggunakan terminal :
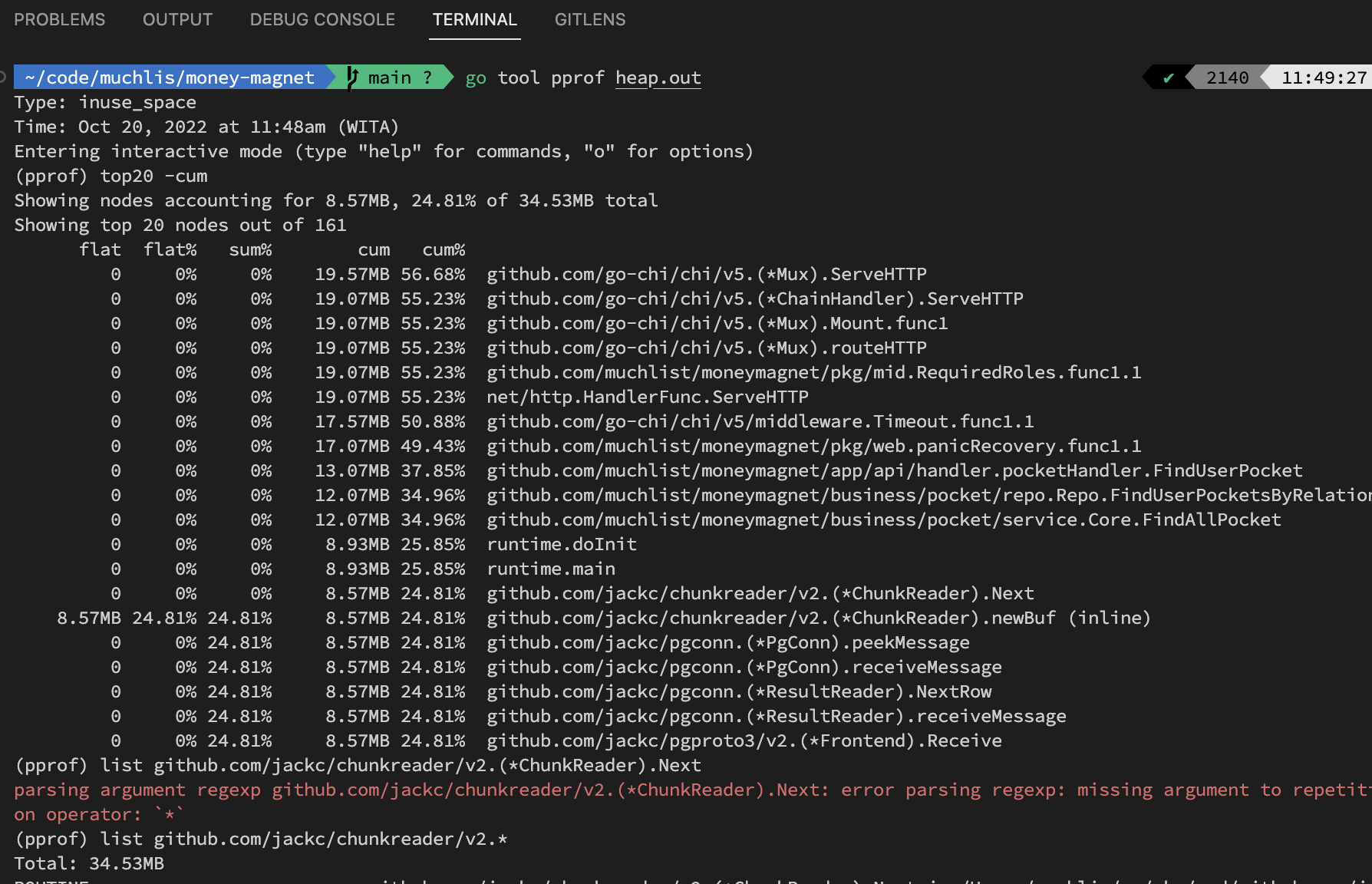
Menggunakan perintah
top20 -cumakan menampilkan fungsi apa saja yang menggunakan memori secara kumulatif (dijumlahkan dengan fungsi-fungsi pada tumpukan di bawahnya). Kita bisa mengabaikan jumlah pemakaian yang wajar. Misalnya,go-chisangat wajar mengendap memori sebesar 19MB karena baru saja dilakukan load test pada service ini.Misal, anggaplah
jack/chunkreadermencurigakan. maka tahap selanjutnya kita bisa jalankan perintahlist github.com/jackc/chunkreader/v2.*(perintah list menggunakan pattern regex)sehingga menampilkan
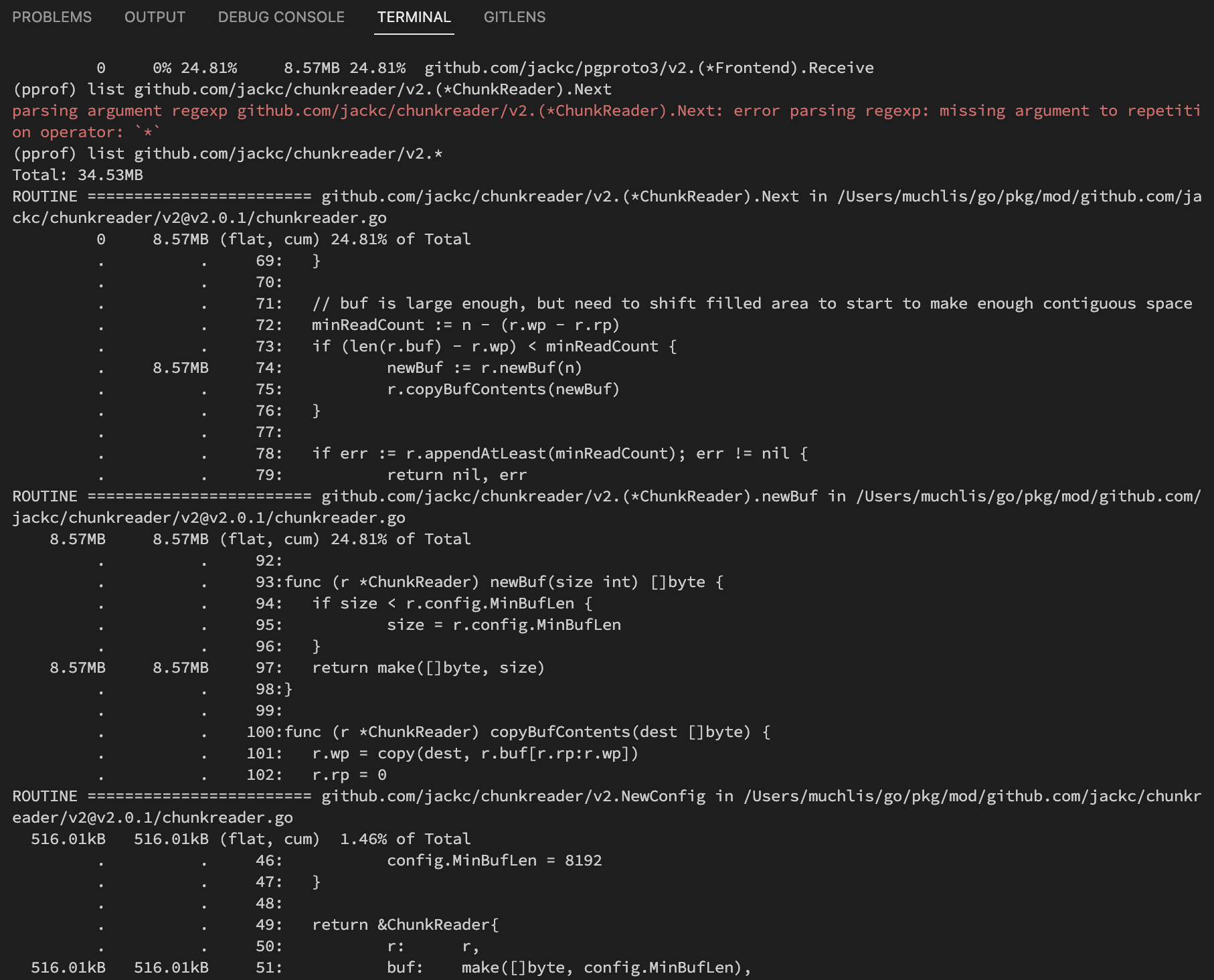
Dari sana kita bisa melihat fungsi mana saja yang dirasa kurang optimal jika memang angkanya tidak pas.
Cara melakukan CPU Profiling
Agak berbeda dengan memory profiling, pengujian CPU harus di-trigger dan dilakukan load pada saat pengambilan data samplenya aktif.
Perintah berikut akan mengaktifkan collect profilling CPU selama 5 detik. (meski saat pengujian tetap dikoleksi selama 30s)
go tool pprof http://localhost:4000/debug/pprof/profile\?second\=5Disaat yang bersamaan, lakukan load test. Bisa menggunakan
hey,jmeteratau tools load test lainnya.Hasilnya akan seperti berikut
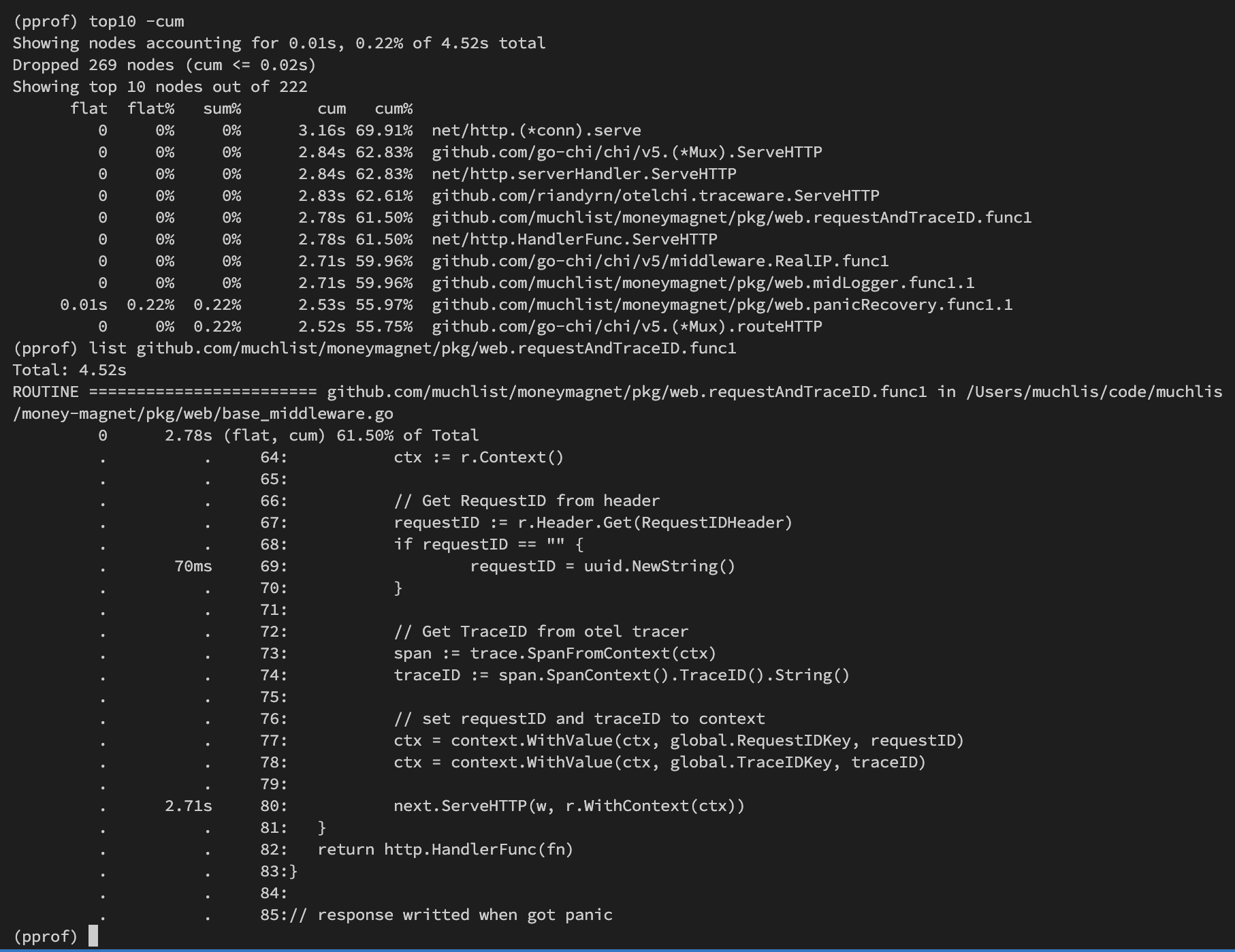
Pada data di atas, saya mengecek middleware buatan sendiri yang ternyata proses lamanya adalah di
next.ServeHTTP, yang mana itu wajar karena perhitungan kumulatif (di bawah fungsi tersebut akan dijalankan program yang sebenarnya, yaitu menuju handler → service → repo).Sample gambar jika melakukan command
png: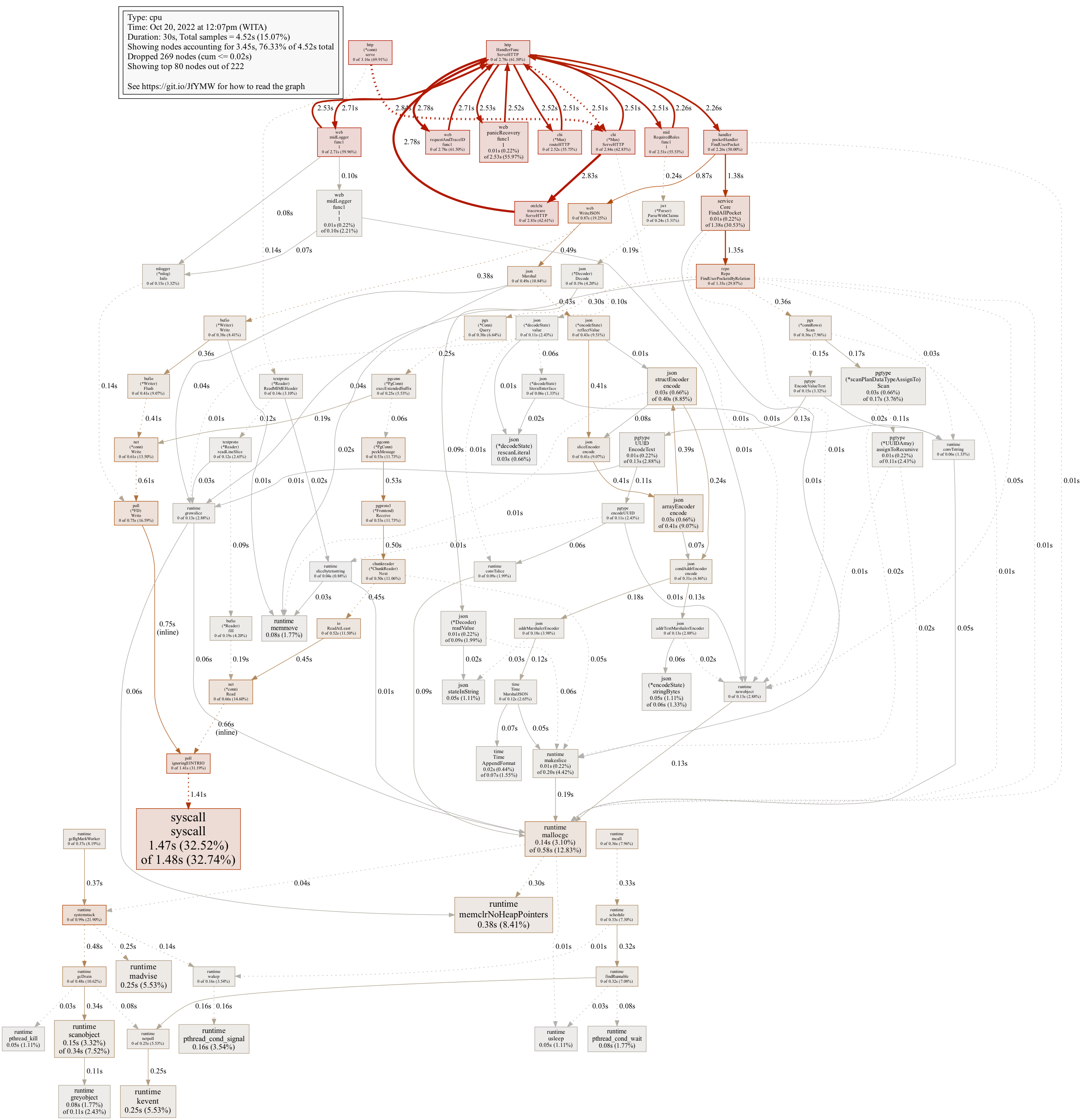
Garbage Collector
Menganalisa performa juga bisa dilihat dari jumlah Garbage Collector (GC) Cycle yang dijalankan dan juga alokasi memori setelah dan sebelum GC. Banyaknya GC Cycle yang berjalan bisa menjadi pertanda penggunaan alokasi memori yang tidak optimal, meskipun tidak selalu. Berikut caranya:
Jalankan program dengan command berikut ini:
# Build dulu program kita go build ./app/api # Command untuk menjalankan program namun hanya menampilkan log gc GODEBUG=gctrace=1 ./api > /dev/nullLog yang di-print pada terminal adalah seperti ini:
gc 1 @0.005s 3%: 0.007+1.6+0.028 ms clock, 0.063+0.12/1.2/0.25+0.22 ms cpu, 3->4->1 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 8 P gc 2 @0.010s 3%: 0.024+0.96+0.002 ms clock, 0.19+0/1.2/0.34+0.022 ms cpu, 3->3->2 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 8 P gc 3 @0.014s 3%: 0.087+1.4+0.005 ms clock, 0.70+0/1.0/1.8+0.044 ms cpu, 5->5->5 MB, 5 MB goal, 0 MB stacks, 0 MB globals, 8 P gc 4 @0.061s 1%: 0.090+1.0+0.019 ms clock, 0.72+0.082/1.4/0+0.15 ms cpu, 11->11->10 MB, 12 MB goal, 0 MB stacks, 0 MB globals, 8 PCara Membaca log:
gc 4artinya selama proses dihidupkan, GC sudah berjalan 4 kali.11->11->10menunjukkan ukuran heap sebelum GC, setelah GC, dan ukuran heap yang masih hidup setelah GC dalam MB (Megabyte).0.090+1.0+0.019 ms clockmenunjukkan waktu yang dihabiskan dalam milidetik (ms) untuk tiga fase utama GC:0.090 msuntuk mark.1.0 msuntuk sweep.0.019 msuntuk waktu stop-the-world (STW).
- 0.72+0.082/1.4/0+0.15 ms cpu menunjukkan penggunaan CPU dalam milidetik (ms) selama fase GC.
- 3->4->1 MB menunjukkan ukuran heap sebelum GC, setelah GC, dan ukuran heap yang masih hidup setelah GC dalam MB.
- 4 MB goal adalah target ukuran heap.
- 0 MB stacks, 0 MB globals menunjukkan memori yang digunakan oleh stack dan global variables.
- 8 P menunjukkan jumlah prosesor (goroutine scheduler threads) yang digunakan.
Analisa performa GC:
- Saat program berjalan, test menggunakan
heyatau tool serupa, misalnya dengan 10.000 request dan lihat berapa jumlah GC yang dihasilkan. - Catat request per second untuk perbandingan
- Jalankan profiling seperti sebelumnya.
go tool pprof http://localhost:4000/debug/pprof/alloc # cari yang paling banyak menggunakan memory top 40 -cum list <name_func>- Saat program berjalan, test menggunakan
Heap analysis:
- Lihat heap apakah tetap kecil atau membesar, jika membesar maka kemungkinan ada memory leak.
- Setelah melakukan perubahan (jika ada) ujicoba lagi dari step 1 dan bandingkan jumlah GC Cycle-nya.
Perbandingan Performa:
- Pastikan penggunaan memori sudah efisien dengan melihat jumlah GC cycle yang terjadi, alokasi heap sebelum dan sesudah GC cycle, serta waktu GC dan waktu stop-the-world (STW).
- Goalnya adalah peningkatan performa yang bisa dibuktikan dengan perbandingan terhadap kode sebelumnya. Caranya bisa dengan membandingkan request per second.
Bagaimana Kita Tahu Kode yang Kita Ubah Menjadi Lebih Baik?
Melakukan profiling seperti diatas dan membandingkan hasilnya.
Menggunakan tools seperti
heyuntuk load test dan membandingkan outputnya, misalnyarequest per second. Catat hasil sebelum diubah dan sesudah diubah.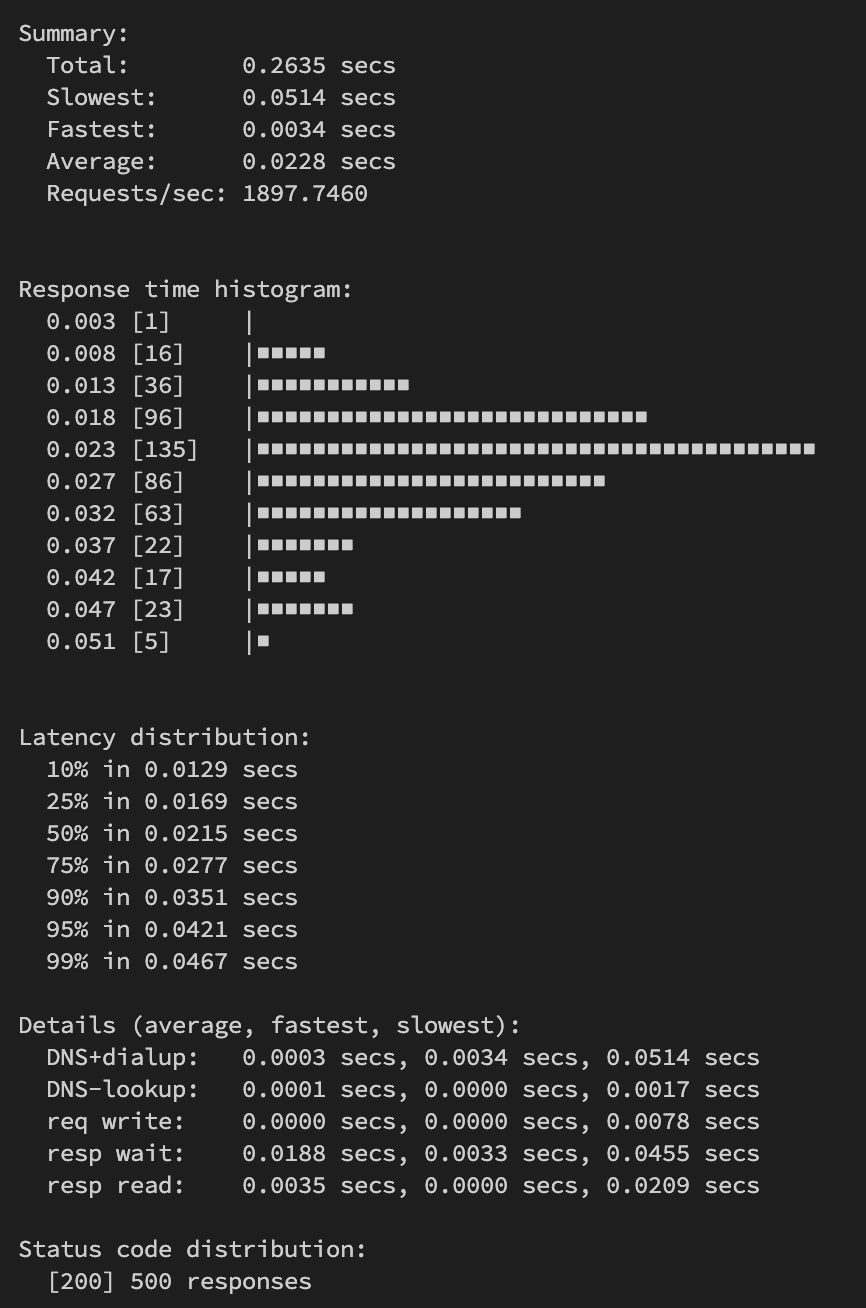
Melihat peforma Garbage Collector ketika dilakukan load test.
Artikel ini menguraikan langkah-langkah penting untuk melakukan profiling di Golang, mulai dari persiapan, modifikasi kode, hingga analisis hasil profiling untuk mengoptimalkan performa aplikasi.